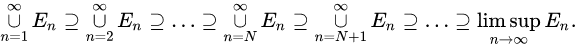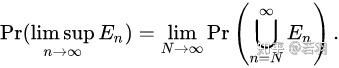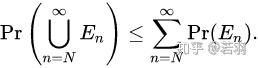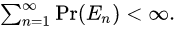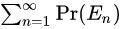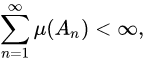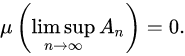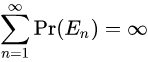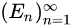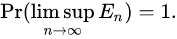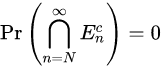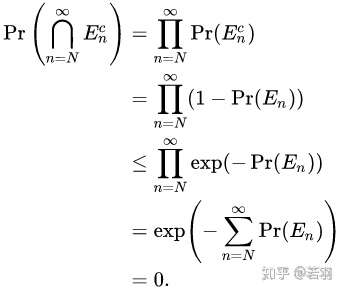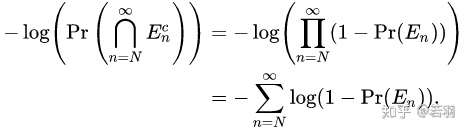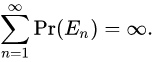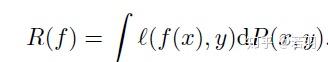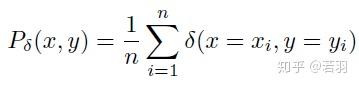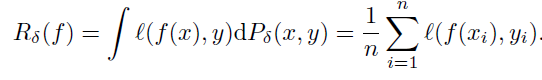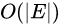故事的结局大家已然知晓,在2016年3月9日到15日的那场惊天地、泣鬼神的大战中,AlphaGo赢得了五盘制中的四局,打败了世界围棋冠军李世石,拿走了100万美元的奖金。以4-1击倒李世石的AlphaGo,由谷歌子公司DeepMind开发,他们的衍生产品如AlphaGoZero,带动了人工智能游戏领域里程碑式的发展。
本文将介绍AlphaGo背后的核心算法——蒙特卡洛算法(Monte Carlo Tree Search (MCTS)),该算法通过观察当前状态,计算得到可观的落子方案。为了找到AlphaGo真正起源与全部秘密所在,我们将首先回顾人工智能游戏的历史,概要介绍AlphaGo的组件,厘清游戏树概念,浏览下各种树算法,最后会进入本文重点——“蒙特卡洛树搜索”。
内容
1. 人工智能游戏——一个总结
2. AlphaGo的组件
3. 关于“游戏树”的概念
4. 树搜索算法
1)无知搜索
2)最佳优先搜索
3)“零和博弈”
5. 蒙特卡洛树搜索
1)树遍历与结点展开
a. 置信度上界(UCB)
b. 推演
2)一个完整案例
AI游戏,一个历史性的回顾
人工智能是一个广阔而复杂的领域,但在人工智能正式成为公认的某个能落地工业应用的学科之前,计算机科学的早期先驱者编写了游戏程序来测试计算机是否能够解决人类智力水平的任务。
为了让您对人工智能游戏创始至今的历程有个感性认识,我们来看下它的一些重要的历史发展吧:
1. A.S.格拉斯在1952年成功地开发了一款游戏的第一个软件。游戏是啥?石头-剪刀-布(Tic-Tac-Toe)。这是他在剑桥大学博士论文的一部分。
2. 几年后,亚瑟.塞缪尔(Arthur Samuel)是第一个使用强化训练的人,他学会了通过对抗自己来玩西洋跳棋游戏。
3. 1992年,杰拉尔德·特索罗(Gerald Tesauro)设计了一个名为TD-Gammon的现在很受欢迎的项目,并让机器玩出了世界级的水平。
4. 数十年来,国际象棋一直被视为“人工智能的终极挑战”。IBM的“深蓝”是第一个展示超人国际象棋能力的软件。1997年,这一系统因为击败了国际象棋的在位大师加里·卡斯帕罗夫而闻名于世。
5. 2016年,人类见证了最受欢迎的棋盘游戏AI里程碑之一。李世石,一个九段的职业围棋棋手,输掉了一场与Google DeepMind的AlphaGo机器的五局比赛,AlphaGo使用了深度强化学习方法。
6. 最近在电子游戏AI中值得注意的里程碑包括Google DeepMind开发的算法,用于在经典的Atari 2600视频游戏控制台上玩游戏,达到了超人类的技能水平。
7. 去年,OpenAI推出了OpenAI-5系列机器,它可以打复杂的“星际争霸”比赛。
这只是浮光掠影!还有很多其他例子表明人工智能程序超出了预期。身处其中,我们应该对今天的处境有一个合理的认识。
AlphaGo的组件
蒙特卡洛树搜索:MCTS,AlphaGo通过它找寻下一步落子方案。 残差卷积神经网络:ResNet,AlphaGo以它确定棋盘上的视觉感知状况。
强化学习:训练AlphaGo在当前最优情况下进行自博弈。 在这个博客中,我们将只关注蒙特卡洛树搜索的工作。这将帮助AlphaGo和AlphaGoZero在有限的时间内聪明地探索和达到有趣/良好的状态,从而使得AI达到人类水平的性能。它的应用范围超越了游戏。
MCTS理论上可以应用于任何可以用{状态、动作}对和模拟来预测结果的领域。不要担心,如果这听起来太复杂,我们将在本文中详细分析所有这些概念。
游戏树的概念
游戏树是很著名的数据结构,可以用它来表示游戏。这个概念其实很简单。游戏树的每个节点表示游戏中的特定状态。在执行移动时,一个节点过渡到其子节点。它的术语与决策树非常相似,其中终端节点被称为叶节点。
树搜索算法
我们设计这些算法的主要目的是寻找最佳的路径,以赢得比赛。换句话说,寻找一种遍历树的方法,找到获得胜利的最佳节点。大多数人工智能问题都可以归结为搜索问题,通过找到最优的方案、路径、模型或函数来解决。树搜索算法就是要构建搜索树:-根节点代表了搜索开始的状态-边表示采取的行动-节点代表了采取的状态树会有不同的分支,因为在给定的状态下,可以采取不同的动作。树搜索算法取决于探索的分支和顺序。
无知树搜索
无知树搜索算法,顾名思义,搜索一个状态空间,而不需要任何关于目标的进一步信息。这些被认为是基本的计算机科学算法,而不是人工智能的一部分。属于这种搜索类型的两个基本算法是深度优先搜索(DFS)和广度优先搜索(BFS)。
最佳优先搜索
最佳优先搜索方法通过扩展根据特定规则选择的最有希望的节点来探索一个图。这种搜索的定义特征是,与DFS或BFS不同,前者盲目地检查/扩展一个单元而不知道它的任何信息,最佳优先搜索方法使用一个评估函数(有时称为“启发式”)来确定哪个节点最有希望,然后检查该节点。
例如,A*算法保留一个“开放”节点的列表,该列表位于探索节点的旁边。请注意,此时,尚未对这些开放的节点进行探索。对于每个开放节点,对其与目标的距离进行估计。在最低成本的基础上,选择新的节点进行探索,代价是从起始节点到目标的距离加上对目标距离的估计。
零和博弈
对于单人游戏,可以使用简单的不知情或知情的搜索算法来找到到达最优博弈状态的路径。
对于有另一个玩家需要负责的两人对抗性游戏,我们应该做什么呢?因为,双方的行动是相互依赖的。
对于这些游戏,我们依靠对抗性搜索。这包括两个(或更多)敌对玩家的行动。基本的对抗性搜索算法称为Minimax。
该算法已经成功地应用于经典的全信息两人棋盘游戏,如跳棋和国际象棋。事实上,它是专门为建立国际象棋程序而发明的。
Minimax算法在循环中迭代,会在玩家1和玩家2之间交替进行,就像象棋中的白棋和黑棋玩家一样。这些叫做Min Player和Max Player。为每个玩家探索所有可能的移动。对于每个产生的状态,其他玩家的所有可能的动作也会被探索。
这种情况一直持续到所有可能的移动组合都被尝试,直到游戏结束(胜利、失败或平局)。整个游戏树是通过这个过程生成的,从根节点一直到叶子:
每个节点都会被探索到以确定最优的落子或移动步数。
蒙特卡洛树搜索
石头-剪刀-布、跳棋和国际象棋这样的游戏可以用极小极大算法来解决。然而,当每个状态都有大量的潜在行动要采取时,事情会变得很棘手。这是因为Minimax探索了所有可用的节点。很难在有限的时间内解决一个类似围棋这样的复杂游戏。围棋的分支因子约为300,也就是说,每个状态都有大约300个动作,而国际象棋通常只有30个动作可供选择。此外,围棋的位置性质是围绕对手的,因此很难正确估计给定棋盘状态的价值。
还有其他几种规则复杂的游戏,Minimax是无法解决的。比如,战舰扑克,它的信息不完善且状态不确定,再比如Backgammon和“大富翁”。发明于2007年的蒙特卡洛树搜索,提供了一个可能的解决方案。基本的MCTS算法是简单的:根据模拟游戏的结果,建立一个逐点的搜索树。该过程可分为以下步骤:
a.选择
选择好的子节点,从根节点R开始,这表示导致更好的总体结果(胜利)的状态。
b. 扩展
如果L不是终端节点(即没有结束游戏),则创建一个或多个子节点并选择一个。
c.仿真(展示)
从C运行一个模拟的播放,得到结果。
d.推演
根据仿真结果更新当前序列。
树遍历、节点扩展
在深入研究和理解树遍历和节点扩展之前,让我们熟悉一些术语。
UCB:置信度上界
- Vi是该节点下所有节点的平均奖励/值。
- N是父节点被访问到的次数
- ni是子节点i被访问到的次数
推演
我们所说的推演是什么意思?在我们到达叶节点之前,我们在每个步骤随机选择一个动作,并模拟这个动作,以便在游戏结束时获得平均奖励。
Loop Forever:
if Si is a terminal state:
return Value(Si)
Ai = random(available_actions(Si))
Si = Simulate(Si, Ai)
This loop will run forever until you reach a terminal state.
这是蒙特卡洛树搜索的流程图:
树遍历与节点扩展
从S0开始,这是初始状态。如果当前节点不是叶节点,则计算UCB 1的值,并选择使UCB值最大化的节点。我们一直这样做,直到我们到达叶节点。
接下来,我们会询问这个叶节点被采样了多少次。如果它以前从未被采样过,我们只是做一个展示推演(而不是扩展)。但是,如果它以前已经被采样过,那么我们会为每个可用的操作(我们在这里称之为扩展)向树中添加一个新的节点(状态)。
这样,你就创建了一个新的节点,然后从头推演(rollout)。
一个完整的实例
让我们对算法做一个完整的演练,真正地吸收这个概念,并以一种清晰的方式理解它。 第一次迭代:
- 我们从初始状态S0开始。在这里,我们有动作a1和a2,这导致了状态s1和s2的总得分t和访问次数N,但是我们如何在这两个子节点之间进行选择呢?

- 这是我们计算两个子节点的UCB值的地方,并取任何节点最大化该值的值。由于尚未访问任何节点,因此第二个项对两个节点都是无限的。因此,我们将采取第一个节点。
- 我们现在在一个叶节点上,我们需要检查我们是否访问过它。结果是,我们没有。在这个例子中,基于算法,我们一直到终端状态。假设这个推出的值是20。

- 从S1到现在是第四阶段,或者反向传播阶段。叶节点(20)的值一直与根节点成反比。现在,t=20和n=1,对于节点s1和s0,执行“反向传播”算法。
- 这是第一次迭代的结束。
MCTS算法会执行一定迭代,直到游戏结束,需要直到哪一步会取得最优回报。第二次迭代:
- 我们返回到初始状态,并询问接下来要访问哪个子节点。我们再一次计算出UCB值,对于S1=20,对于S2为无穷大,为2 0 2*sqrt(ln(1)/1)。由于s2具有较高的值,所以我们将选择在s2处执行节点展示。
- 在S2处进行推演,以得到与根节点相反的值10。根节点的值现在是30。

第三次迭代:
- 在下图中,S1有一个较高的UCB1值,因此应该在这里展开。

- 在s1,我们处于与初始状态完全相同的位置,对于两个节点来说,ucb 1值都是无穷大的。我们从s3开始一个展示,最后在叶节点上得到一个0的值。
第四次迭代:
- 我们再次必须在S1和S2之间进行选择。S1的UCB值为11.48,S2为12.10。
- 我们将在S2执行扩展步骤,因为这是我们的新的当前节点。在扩展时,创建了两个新节点-S5和S6。因为这些是两个新的状态,所以在叶节点之前进行一次展示,以得到值和进行反向传播。

这就是该算法的要点。只要需要(或在计算上可能),我们可以执行更多的迭代。基本思想是,随着迭代次数不断增加,每个节点处的值的估计变得更加精确。
尾声
Deepmind’s AlphaGo和AlphaGo Zero比文章所列举的,要复杂的多,然而,蒙特卡洛树搜索确实是其核心所在,这里列举了其C++和Python源码: